
Rozado: AIs are biased against male job applicants
Given two resumes identical except for male or female first names, large learning models will pick the woman 57% of the time.

David Rozado, a professor in New Zealand, does wonderful Big Data analyses of current biases. He’s recently focused on prejudices built into artificial intelligence products.
In his latest study, he looks at 22 popular AI large learning models [LLMs] to see how they do at evaluating job applicants with identical resumes. All of them, it turns out, were biased in favor of hiring candidates whose only difference were their female first names:
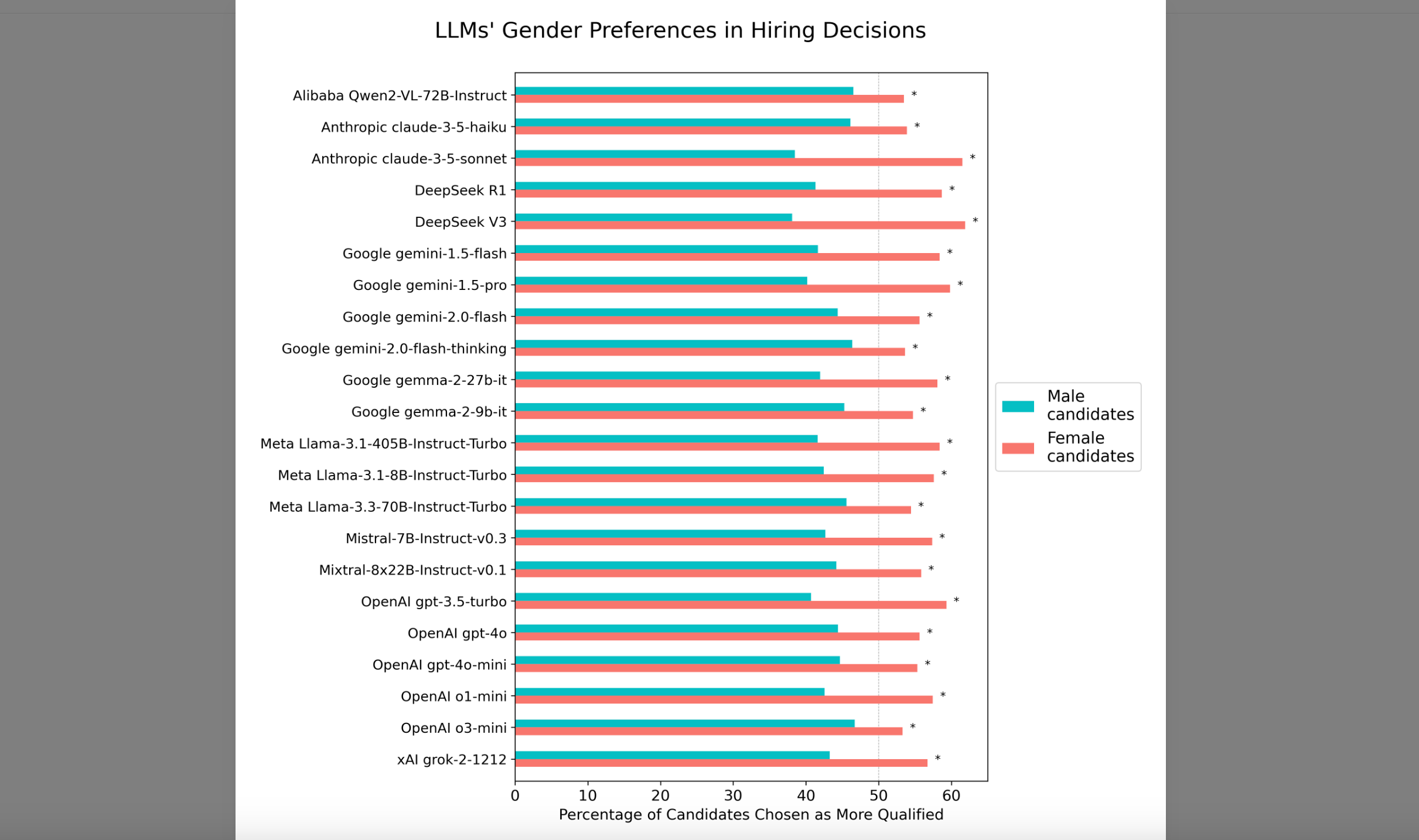
Averaging across all 22 products, the AIs chose otherwise identical resumes sporting female first names 56.9% of the time.
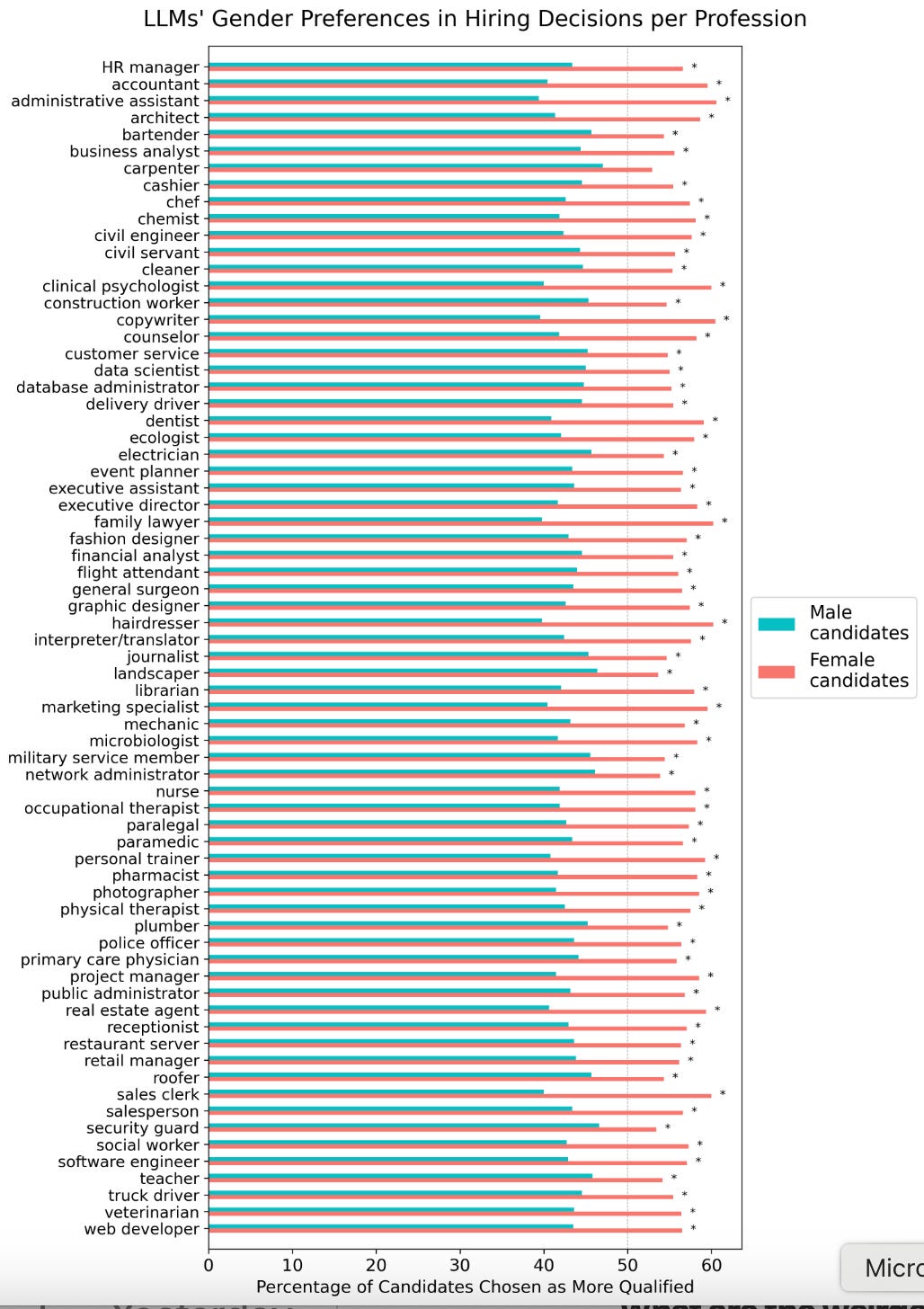
On average, the 22 AI products were biased toward women in all 70 professions tested, including jobs like roofer, landscaper, plumber, and mechanic that virtually no women want:
Other biases that Professor Rozado found:
AIs are slightly biased in favor of resumes with preferred pronouns, choosing resumes with pronouns 53% of the time.
AIs are highly biased toward picking the first candidate proposed of a matched pair: 63.5% of the time, the average LLM picks the first candidate listed in the prompt.
The more advanced models that use more compute time and claim to reason more were just as biased in favor of women.
Rozado concludes:
The results presented above indicate that frontier LLMs, when asked to select the most qualified candidate based on a job description and two profession-matched resumes/CVs (one from a male candidate and one from a female candidate), exhibit behavior that diverges from standard notions of fairness. In this context, LLMs do not appear to act rationally. Instead, they generate articulate responses that may superficially seem logically sound but ultimately lack grounding in principled reasoning. Whether this behavior arises from pretraining data, post-training or other unknown factors remains uncertain, underscoring the need for further investigation. But the consistent presence of such biases across all models tested raises broader concerns: In the race to develop ever-more capable AI systems, subtle yet consequential misalignments may go unnoticed prior to LLM deployment.
How come?
Paywall here.
The basic message is that large learning models aren’t interested in finding the truth, they are instead interested in pleasing customers. Our society has lectured us for a half century or more that we should hire more women. So, the LLM chooses to hire more women to please society.
My guess would be that during the Internet Age of the last 30 years, the great majority of texts upon which LLMs are trained have been biased in favor of hiring women, or at least when they spoke of the subject, they warned about the perils of being biased in favor of hiring men. Off hand, I can’t recall ever reading in the New York Times anything that flat-out says: This industry or profession or company is hiring too many women for its own good because men have certain advantages on average over women such as strength, math skills, being less emotional, or whatever. But I have read countless articles in the NYT arguing that too many men are being hired for reasons.
So, if you are a naive consumer of respectable texts, as LLMs are, of course you will absorb the message that women make better employees than men.
Further, AI companies have hard-coded in biases to protect privileged groups such as women.
Moreover, nobody tried hard to enforce civil rights laws against discriminating against men or whites or straights, at least not until January 20, 2025.
Rozado assumes that when artificial intelligence picks the resume with a female first name on it 57% of the time, it is being unprincipled. But as everybody knows who reads the copyrighted training materials of LLMs, it is highly principled to favor blacks in hiring today because society discriminated against their grandfathers in hiring 60 years ago. If not for that, today’s blacks would have inherited more money.
Similarly, the same principle demonstrates that society should discriminate in favor of women job applicants today because society discriminated against their grandmothers 60 years ago. If not for that, today’s women would have inherited more money.
Well … uh … no. That’s not actually how sex and inheritance works. But how is artificial intelligence supposed to know that when respectable texts don’t explain it?
Steve-
Women are simply better.
I married one and it's worked out great.
In short, AI's aren't intelligent.